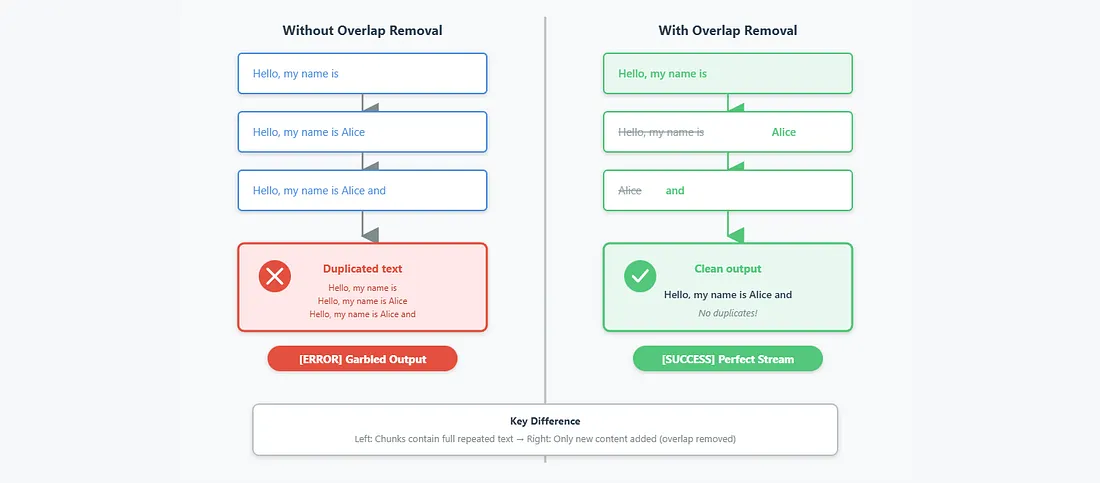
How overlap removal works in LLM streaming generation (async/sync)?
Text duplication and overlap are common challenges when streaming or batch-generating text with LLMs. Models can repeat themselves, particularly when:
- generating in overlapping contexts, or
- decoding produces partial repetition (common with long outputs).
While examining SGLang’s offline and streaming generation APIs, I noticed this issue firsthand. Although overlap removal and overlap-awareness mechanisms exist to mitigate it, exploring these techniques reveals how clean, readable real-time text can be ensured.
This approach is essential for production-grade LLM streaming. Frameworks like SGLang enhance it further with optimizations such as RadixAttention and continuous batching for high-performance inference.
📖 Read the blog post on Medium:
Understanding the Hidden Mechanism That Keeps Your LLM Streaming Text Clean (Async & Sync)