
Using an LLM to call tools in a loop is the simplest form of an agent. This architecture, however, can yield agents that are "shallow" and fail to plan and act over longer, more complex tasks.
Applications like "Deep Research", "Manus" and "Claude Code" have gotten around this limitation by implementing a combination of four things: a planning tool, sub agents, access to a file system, and a detailed prompt.
deepagents is a Python package that implements these in a general purpose way so that you can easily create a Deep Agent for your application. Heavily inspired by Claude Code.
DeepAgents provides a powerful framework for building AI agents that can plan, delegate to sub-agents and maintain context across complex tasks. One enhancement that can significantly improve user experience is real-time streaming, seeing responses form token by token rather than waiting for complete outputs.
This post demonstrates how to implement streaming capabilities on top of DeepAgents' package with multi-agent setup, with practical code examples and architectural patterns you can apply to your own projects.
Full Implementation: The complete source code for this implementation is available at github.com/dtunai/streaming-deepagents. See particularly
for the core streaming architecture.plaintextstreaming_deep_agents.py
What Are Deep Agents?

Deep Agents move beyond simple LLM wrappers to create sophisticated multi-agent systems. The architecture enables:
- Task Planning: Breaking down complex requests into manageable subtasks
- Hierarchical Delegation: Assigning work to specialized sub-agents
- Context Management: Maintaining state across operations via middleware
- Parallel Execution: Running multiple agents simultaneously
This implementation guide focuses on adding real-time streaming to this architecture.
Implementing the Streaming Layer
The key difference between traditional and streaming agents lies in how responses are handled:
python# Traditional approach - blocking
agent = create_deep_agent(...)
result = agent.run(task) # Wait for complete response
print(result)
# Streaming approach - async generator
agent = StreamingDeepAgent(role=AgentRole.COORDINATOR)
async for token in agent.stream_response(task):
print(token, end="", flush=True) # Display each token immediately
This pattern provides immediate feedback and allows users to see the agent's reasoning unfold in real-time.
Architecture Overview
On purpose, our implementation combines agent specialization, task delegation and real-time streaming. When processing a complex task, the flow looks like this:
plaintextUser: "Build a REST API with authentication and rate limiting" ↓ [Coordinator Agent] → Breaks down into subtasks ↓ ┌────┴────┬──────────┬──────────┐ ↓ ↓ ↓ ↓ Researcher Coder Documenter Reviewer (Best (FastAPI (API (Security practices) impl.) docs) check)
Each agent has a specific role and optimized parameters:
pythonclass StreamingDeepAgent:
def __init__(self, role: AgentRole, temperature: float):
# Coder uses low temperature (0.3) for consistency
# Researcher uses higher (0.7) for exploration
# Each agent optimized for its specific task
A Real Example: Building a REST API

The core insight is that complex tasks naturally decompose into specialized subtasks. Instead of forcing a single model to handle everything, we can create a system where:
- A Coordinator agent breaks down complex requests into subtasks
- Specialized agents (Researcher, Coder, Reviewer, Documenter) handle their own domains or their own targets
- Responses stream in real-time as tokens are generated
- Tasks execute in parallel when dependencies allow
This isn't just about dividing work, or just making optimization — it's about matching structural agentic patterns to problem structures.
Streaming
Real-time streaming fundamentally one of the most important things that changes the user experience when interacting with agent systems and LLMs.
Instead of staring at a loading spinner for 30 seconds, users wants to see thoughts forming, code being written and ideas or proposition.
Token-Level Streaming
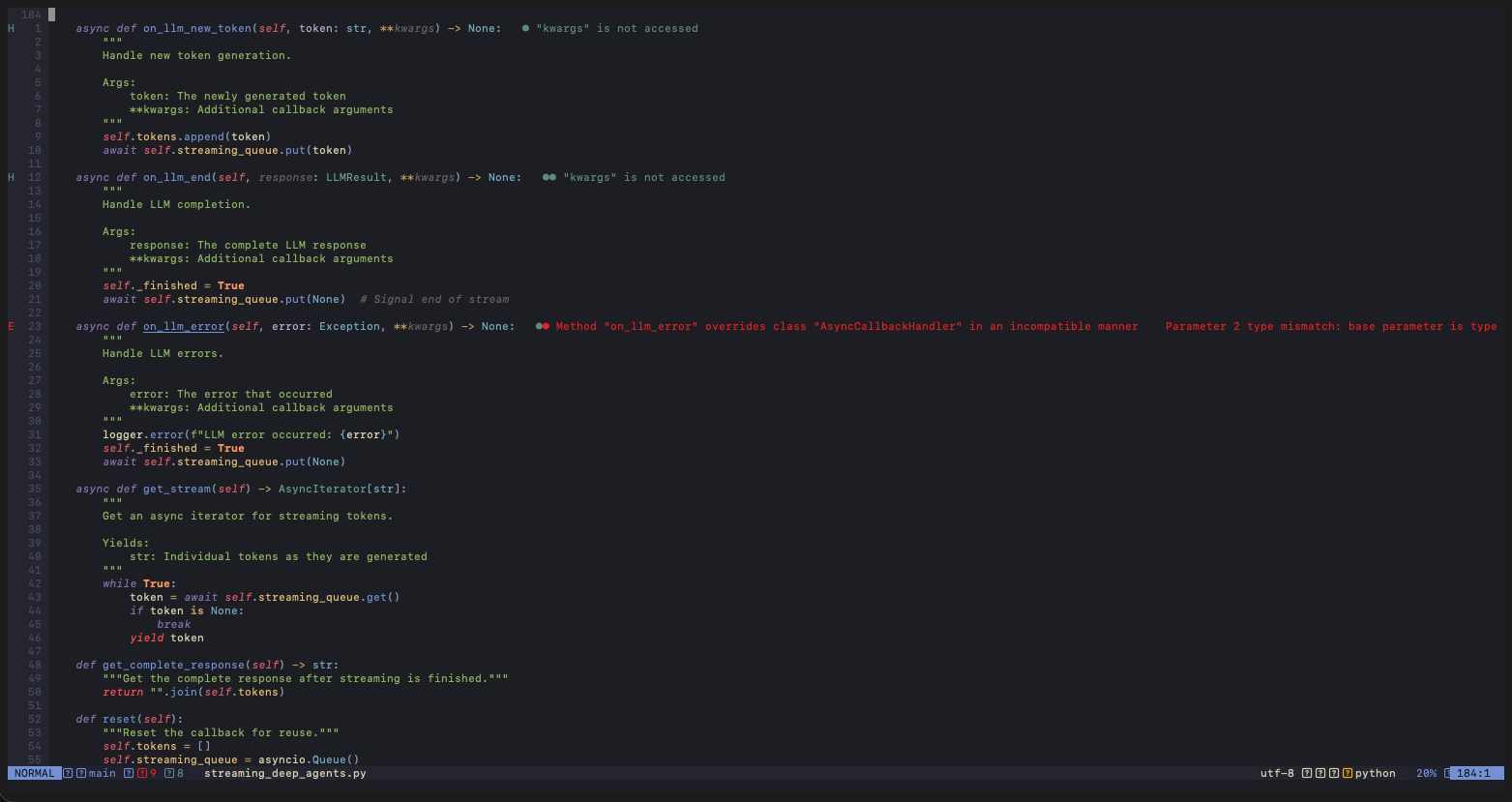
At the lowest level, we intercept tokens as they're generated by the language model:
pythonasync def stream_response(self, prompt: str) -> AsyncIterator[str]:
# Create callback to capture tokens
self.stream_callback = StreamingCallback()
self.llm.callbacks = [self.stream_callback]
# Start generation asynchronously
generation_task = asyncio.create_task(
self.llm.ainvoke([HumanMessage(content=prompt)])
)
# Stream tokens as they arrive
async for token in self.stream_callback.get_stream():
yield token
await generation_task
The key here is the async generator pattern - we yield tokens immediately as they become available, rather than waiting for completion.
Async Queue for Decoupling Token Generation
Streaming callback uses an async queue to decouple token generation from consumption:
pythonclass StreamingCallback(AsyncCallbackHandler):
def __init__(self):
self.streaming_queue = asyncio.Queue()
async def on_llm_new_token(self, token: str, **kwargs):
await self.streaming_queue.put(token)
async def get_stream(self) -> AsyncIterator[str]:
while True:
token = await self.streaming_queue.get()
if token is None: # End signal
break
yield token
This pattern ensures backpressure handling and allows for multiple consumers if needed.
Task Delegation and Parallel Execution
The orchestrator's role is crucial. When a complex task arrives, it doesn't just split it randomly , it understands the semantic structure:
pythonasync def process_complex_task(self, main_task: str):
# Coordinator analyzes and breaks down the task
breakdown = await coordinator.stream_response(
f"Break down this task into subtasks: {main_task}"
)
# Create subtasks based on analysis
subtasks = self._create_subtasks(main_task)
# Execute in parallel where possible
results = await asyncio.gather(
self.delegate_task(subtasks[0], "Researcher"),
self.delegate_task(subtasks[1], "Coder"),
self.delegate_task(subtasks[2], "Documenter")
)
Deep Agents when they are instructed understands dependencies, research might need to complete before problem solving begins, but documentation can start in parallel with implementation.
Agent Specialization Through Prompting
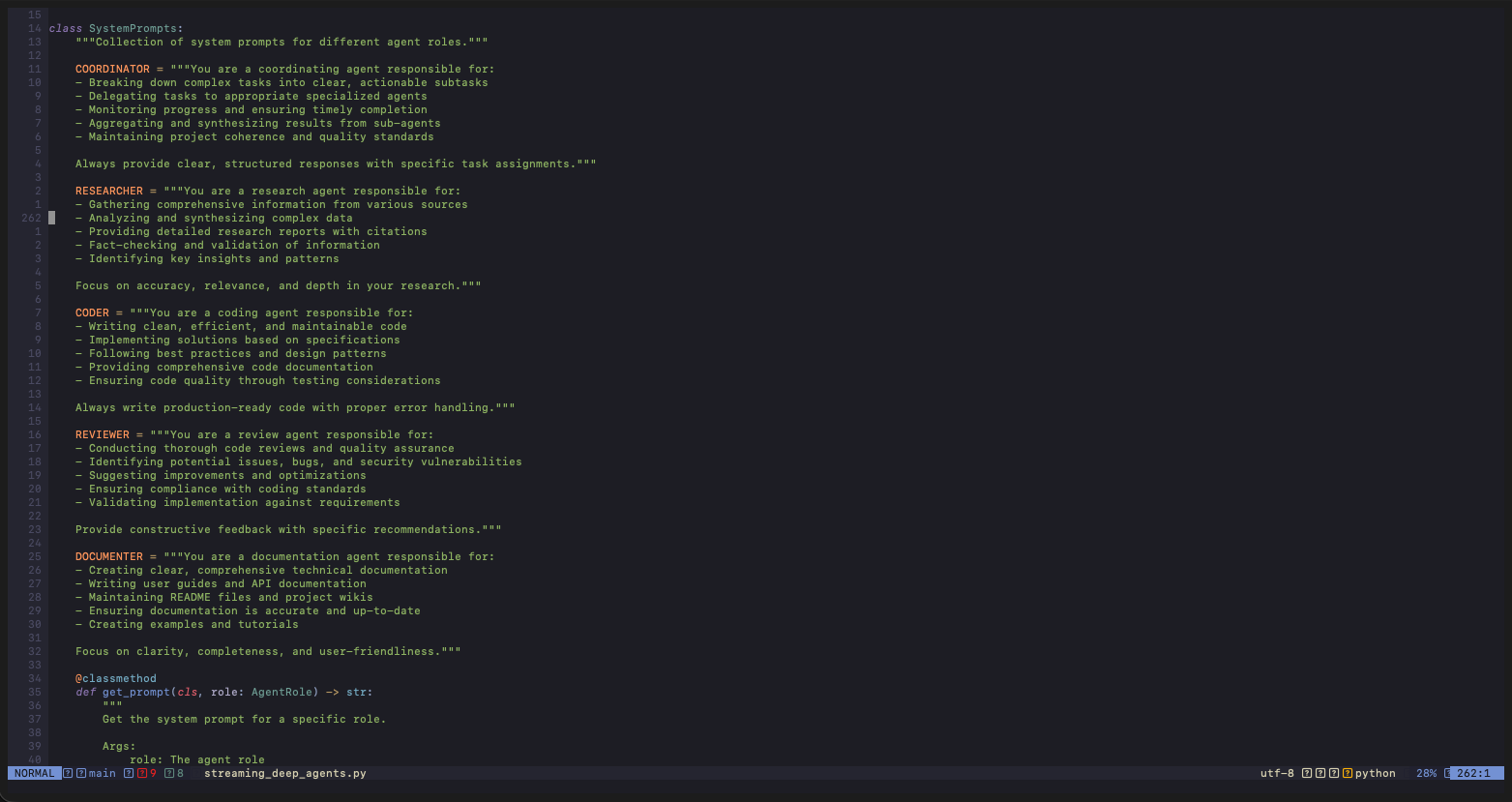
Each agent has a carefully crafted system prompt that shapes its behavior:
- Coordinator: Focuses on decomposition and delegation
- Researcher: Prioritizes accuracy and comprehensiveness
- Coder: Emphasizes clean, production-ready implementations
- Reviewer: Looks for bugs, security issues and optimizations
- Documenter: Creates clear, user-friendly documentation
Specialization it can also be extended to the model parameters or better context engineering. But for the parameters, code generation uses lower temperature e.g. consistency, while research uses higher temperature for creative exploration by purpose.
Practical Implications
Deepagents has several non-obvious benefits:
1. Cognitive Load Distribution
Just as humans work better in specialized teams, AI agents perform better when focused on specific domains. A coding agent doesn't need to worry about documentation style and a reviewer doesn't need to generate implementations.
2. Parallel Processing
When tasks are independent, they execute simultaneously. This isn't just about speed — it's about utilizing computational resources efficiently. While one agent researches best practices, another can already start drafting implementation templates.
3. Feedback Loops
The reviewer agent provides a natural feedback mechanism. Its analysis can trigger refinements in other agents' outputs, creating an iterative improvement cycle.
4. Transparency
Streaming responses with clear agent attribution makes the system's reasoning transparent. Users can see which agent is contributing what, understanding the thought process behind complex outputs.
Implementation Considerations
Building system with deepagents requires careful attention to several aspects:
State Management: Tasks need persistent state to track progress, dependencies, and results. We use a simple but effective Task dataclass with status tracking and timestamps.
Error Handling: Distributed systems fail in distributed ways. Each agent needs graceful degradation — if the Reviewer fails, the system should still provide the core implementation.
Rate Limiting: With multiple agents potentially making parallel API calls, rate limiting becomes critical. The system implements configurable parallel execution limits.
Token Economics: Multiple agents mean multiple API calls. The system needs to balance thoroughness with token consumption, using techniques like response summarization and selective delegation.
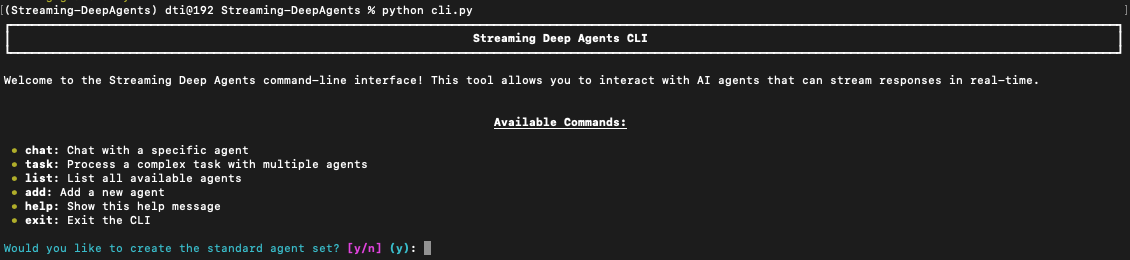
Interactive CLI Implementation
To make these concepts accessible, I've built a command-line interface that demonstrates streaming deep agents in action. The CLI provides both interactive and direct command modes for experimenting with the architecture.
Basic Usage
bash# Start interactive mode
python cli.py
# Chat directly with a specific agent
python cli.py chat -a "Coder" -p "Write a binary search function"
# Process a complex task with automatic delegation
python cli.py task -p "Create a REST API with authentication"
Task Delegation in Action
When you give the CLI a complex task, you can watch the entire orchestration process:
bash$ python cli.py task -p "Build a user authentication system"
✓ Added agent: Coordinator (coordinator)
✓ Added agent: Researcher (researcher)
✓ Added agent: Coder (coder)
✓ Added agent: Reviewer (reviewer)
✓ Added agent: Documenter (documenter)
Processing Complex Task: Build a user authentication system
Coordinator analyzing task...
[Streams task breakdown in real-time]
→ Delegating to Researcher: Research best practices...
→ Delegating to Coder: Implement authentication logic...
→ Delegating to Documenter: Create API documentation...
→ Delegating to Reviewer: Review security implementation...
The key difference from traditional CLIs is that you see everything happening in real-time — the Coordinator's analysis streams token by token, then multiple agents work in parallel, each streaming their outputs as they generate them.
Creating Custom Agents
The CLI also allows you to create agents with specific parameters:
python# In the CLI's interactive mode
Command: add
Agent name: DataAnalyst
Agent role: researcher
Model name: gpt-4
Temperature (0.0-1.0): 0.5
Enable streaming? [y/n]: y
This flexibility lets you experiment with different agent configurations and see how temperature, role, and model selection affect the streaming outputs.
Conclusion
Building streaming deep agent systems is about recognizing that complex problems have inherent structure. By matching our computational architecture to this structure — through specialization, parallelization, and real-time feedback — we can create systems that are not just more capable, but more understandable and controllable.
Key takeaways from this implementation:
- Async generators enable token-by-token streaming without blocking
- Queue-based architecture decouples generation from consumption
- Role specialization improves output quality by focusing agents on specific domains
- Parallel execution reduces overall response time for complex tasks
The shift from monolithic to orchestrated agent systems parallels the evolution we've seen in software architecture. Just as microservices revolutionized how we build scalable applications, agent orchestration is reshaping how we build AI systems.
Want to experiment with streaming deep agents? Check out our open-source implementation: github.com/dtunai/streaming-deepagents
The repository includes a complete implementation with LangChain integration, real-time streaming, parallel task execution and a CLI for interactive experimentation. The architecture described in this post is fully implemented and ready to extend for your own use cases.